




Hi every one in this blog I would like to explain about Kubernetes Volumes.
We need volumes to persist the data in the pod. Like how we have docker volumes in Kubernetes also we have volumes to store the data.
The 2 Problems volumes has to solve
Sharing Data across the replicas of the pod
Persisting Data
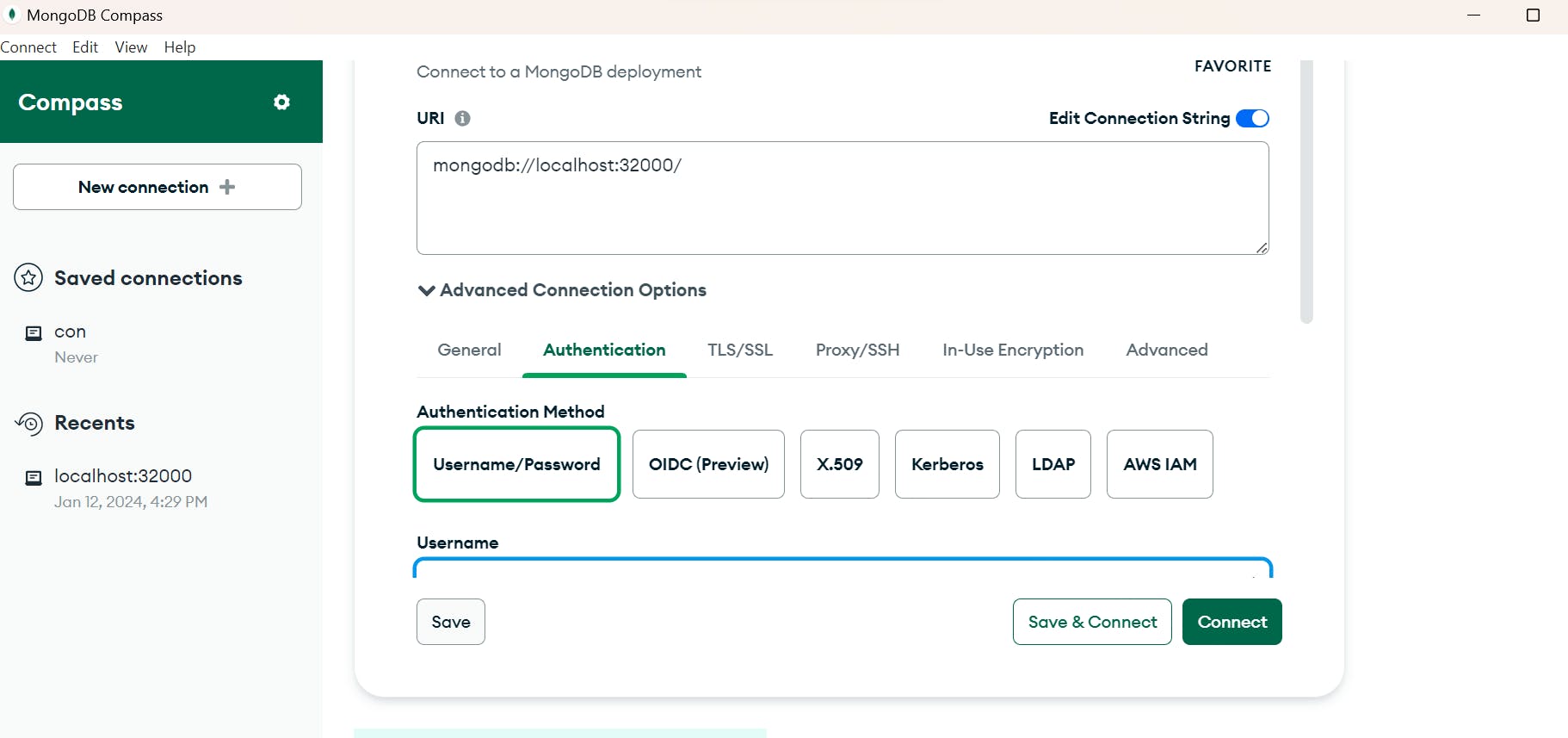
Let us take the example of deploying mongo db database as deployment and by attaching a node port service. Using mongo compass which is mongo UI ,let us access database.
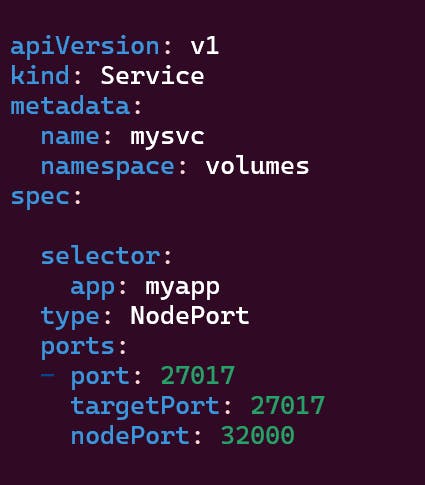
Lets port forward the service using
kubectl port-forward svc/mysvc 32000:27017
32000 is the nodePort and 27017 is the container port.
I hope every one who are reading this article has a basic knowledge on services and deployments.
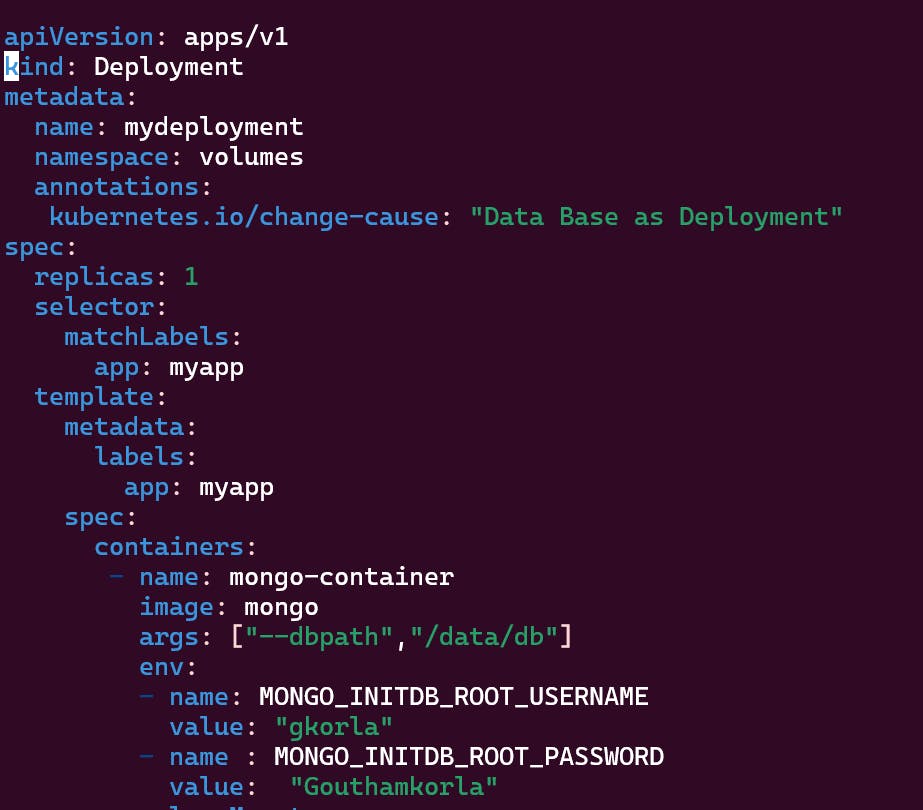
These are the deployment file and service attached to it.
Using the root username and password lets connect to the database.
Storing Data at Container Level
If we insert data to this pod through mongo compass , data inside container can persist as long as the container is alive after container restarts all the data stored will be vanished.
So lets delete container by going inside the pod using

Using ps aux which lists all the process running inside container lets delete that mongo process using

1 is the process id of mongo db process. We can look at the data in /data/db path this is where mongo container stores data .
After killing container, Kubernetes restarts the container and all the data will be lost.
Here no other container can share data except this container and there is no persistence of data.
Storing Data at Pod Level
Here though container dies as the data stored in pod level container can use this data.
Using emptyDir we can create a path in pod using same name as the pod volume in volume mounts we can connect to the emptyDir pod volume and all the data stored in mountPath.
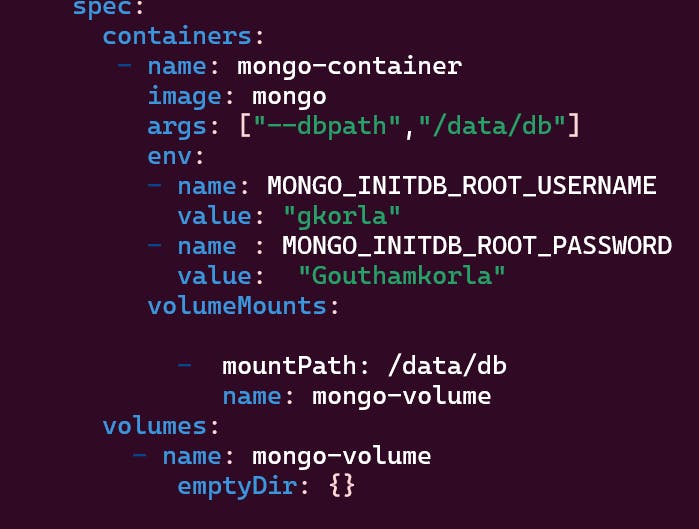
Pod is also ephimeral as container so if the pod restarts then data stored will be vanished and also other replicas will not share the data in this pod .
If the data stored in the node other pods will be able to share though pod dies as the data is in the node no problem. But if the pod is in the other node then those pods will not be able to share the data on this node more over if the node dies all the data will be vanished again.
So to persist data kubernetes has 3 main components
Persistent Volume
Persistent Volume Claim
Storage Class
Persistent Volumes
Persistent Volume is the abstract component it has to take the storage from actual storage like AWS EBS , NFS , local disk etc.
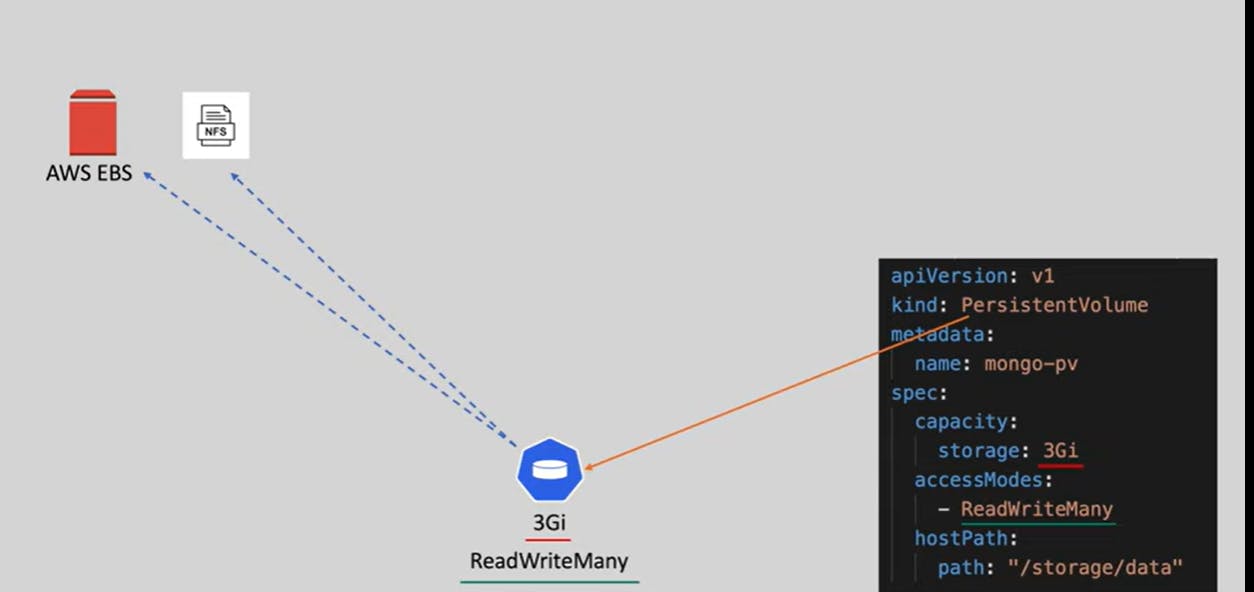
It can be created from usual YAML manifests.
3GB storage will now be created here we have used local disk to store data in /storage/data .
There are different access modes
ReadWriteMany which means this volume can be used my many nodes if the pods are running on different nodes we can use this.
ReadWriteOnce which means volume can be used my only one node.
ReadOnlyMany / ReadOnlyOnce (Self Explainatory)
ReadWriteOncePod which means only one node can use this volume.
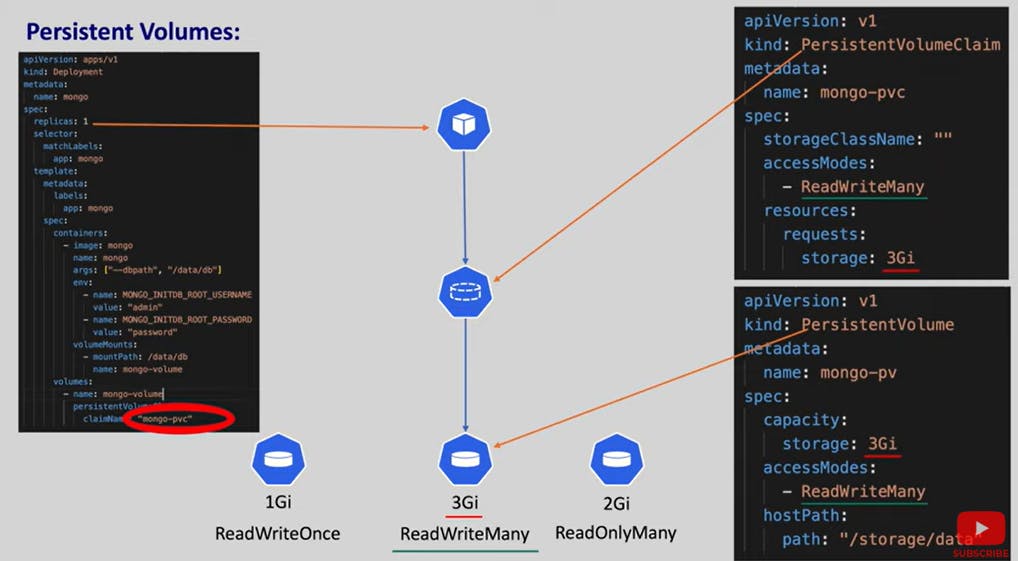
PersistentVolumeClaim
By using persistent volume claims which is another resource we can connect the persistent volumes to the pod.
Using storage and access modes, persistent volume claim selects the correct persistent volume.
kubectl get pv // For persistent volumes
kubectl get pvc // For Persistent volume claims
Using the name of the persistent volume claims under volumes section in deployment file pods can use the persistent volumes through persistent volume claims.
Now though we delete the pods , nodes even pv, pvc's data will never be vanished.
pv , pvc's cannot be deleted if they are in use to delete them we have to delete the pods using the pvc's and the pvc's using the pv.
Storage Class
Instead of creating pv's ourselves with different storages we can create dynamically using storage class which reduces our work.
It uses pvc to create pv with provided accessmode and storage.
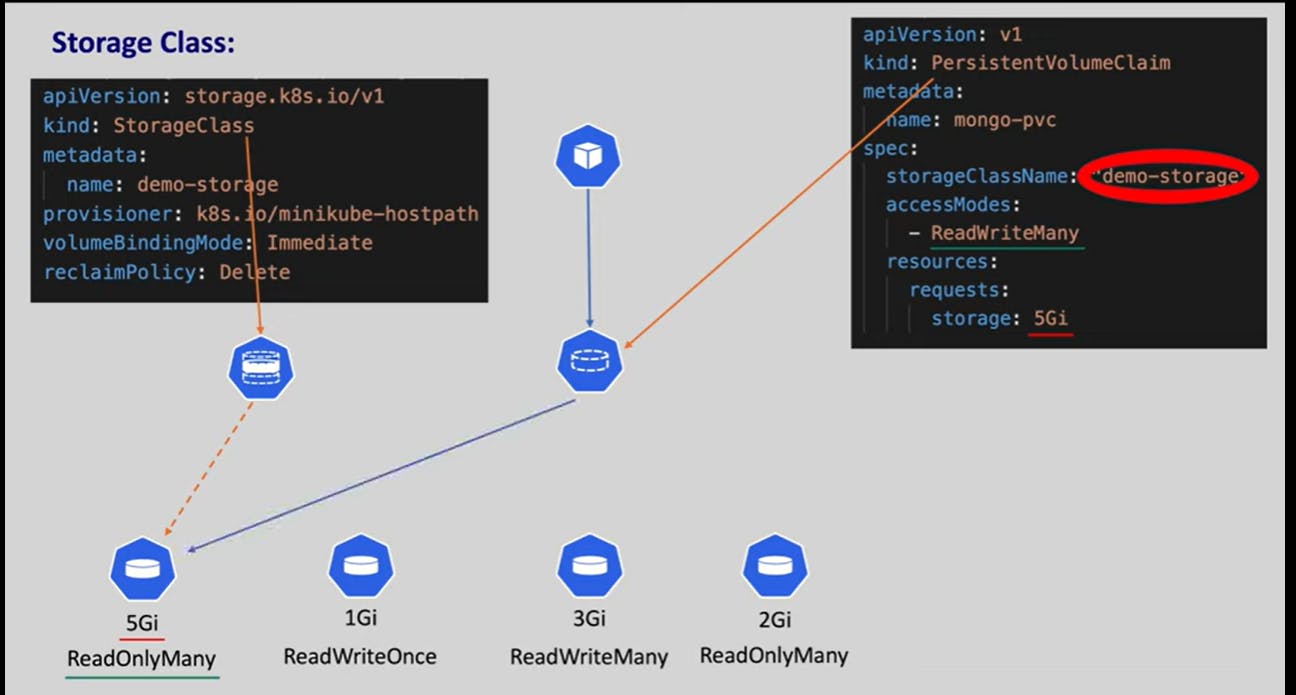
provisioner is whose storage we are using here we are using local disk we can use AWS EBS , NFS etc.
volumeBIndingMode can be
Immediate which means after creating pvc immediately pv will be created through storage class.
WaitForFirstConsumer which means after pvc is bound by pod then pv will be created.
reclaimPolicy can be
Delete which means if the pvc was deleted then corresponding pv will also be deleted.
retain which means if pvc deleted pv will not be deleted.
kubectl get sc // For storage class
By default we have standard storage class that every pvc will use.
If we overwrite our storage class name in pvc then instead of standard storage class, then our storage class will be used by pvc.
In minikube by default every pvc will use standard storage class and use pv created by this storage class and our created pv will be neglected.
To avoid this replace false with true in storageclass.kubernetes.io field.
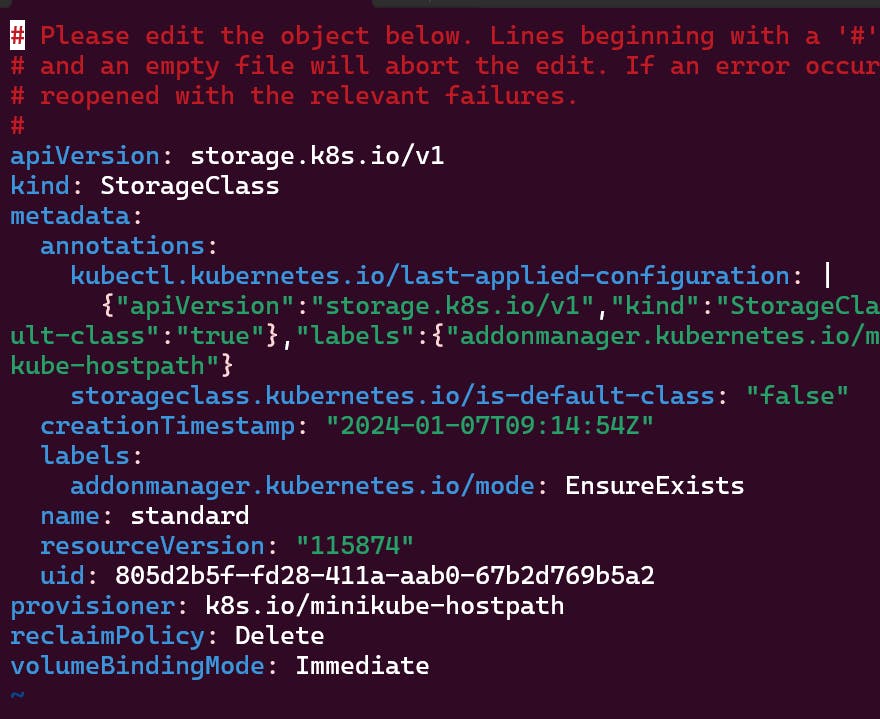
If we create our own storage class then there is no problem.
pvc's are namespaced and pv's and sc's are not namespaced.
Now other replicas can use the data used by on replica and data was persisted irrespective of pod/node health.
That's it about Kubernetes volumes. Thanks for reading my blog have a great day.